| R数据分析:广义估计方程式GEE的做法和解释 | 您所在的位置:网站首页 › mmrm模型 R语言 › R数据分析:广义估计方程式GEE的做法和解释 |
R数据分析:广义估计方程式GEE的做法和解释
|
好久没有更新文章了,因为同学们咨询的问题有点多,另一个原因就是自己实在太懒。。。。 今天继续给大家写广义估计方程式GEE。 In statistics, a generalized estimating equation (GEE) is used to estimate the parameters of a generalized linear model with a possible unknown correlation between outcomes. 上面的英文解释告诉我们,当我们想用广义线性模型的时候,突然发现我们的结局变量恐怕是有某种相关性的(比如重复测量,比如嵌套),我们就可以考虑广义估计方程了。 实例说明还是来看例子:现在我手上有来自两个病区患有呼吸系统疾病共111个病人,分为治疗组和安慰剂组,进行纵向随访4次,每一次随访我们会记录病人情况(1 = good, 0 = poor) 于是得到我们的数据,大概长这样: 
其中,我们的响应变量有4个,因为我们随访了4次嘛,拿到上面的数据,我现在问你治疗到底有没有作用? 你该如何分析上面的数据? 首先我们明确我们的研究问题是治疗效果,就是说我们想看治疗组A和安慰剂组P是不是在响应变量上有差异。 我们遇到的问题在于响应变量有4个,怎么办呢? 反正你肯定知道只选其中一个响应进行分析肯定是不对的,把4次响应求均值肯定也是不对的,4次响应都当作独立的观测肯定也是不对的。 我们必须想办法利用全部的响应变量,而且还需要考虑同一个人的4次响应之间的相关性。 嘿嘿,怎么做呢? 混合效应模型? 可以,不过今天我们的主角是广义估计方程式。 广义估计方程和混合模型的根本区别就在于它把并不是很关注组内的相关,而是把重点放在了对效应均值的建模上,为了更好地理解GEE我们先看两个概念: The very crux of GEE is instead of attempting to model the within-subject covariance structure, to treat it as a nuisance and simply model the mean response. 方差函数与均值函数假设我们有独立响应变量
有如下关系:
其中
称 那么,我们的主要目标就是估计β向量。大家也可以看出来相比广义线性模型,广义估计方程式,就是多了方差函数。 边际模型与条件模型这个有点难哦,因为没怎么学过矩阵运算,所以我只能尝试性地给大家解释一波,不一定哈。 之前有给大家写很多混合模型的文章,回忆一下混合模型是如何控制组间相关性的,是通过估计随机效应实现的: 混合模型的模型表达是这样: 
有固定效应β,有随机效应u,那么这么一个模型也可以看作是一个条件模型。 怎么讲? 就是如果我们令残差e的变异为σ 2 I,在随机效应u存在的情况下,y的分布为: 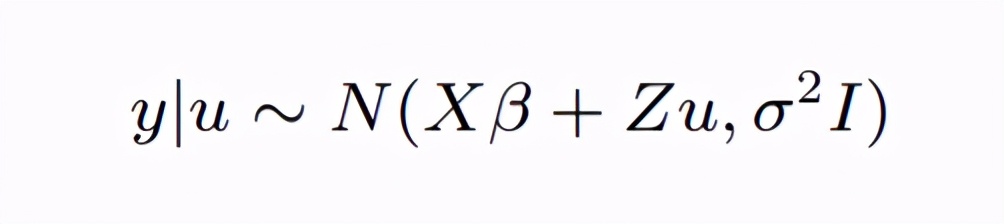
这个应该没问题吧,因为我们已经考虑了u,考虑u之后我们认为方差齐的情况下,因变量就是独立的啦,因为混合效应的假设之一就是随机效应服从正态分布嘛。 再看边际模型 所谓边际模型在我的理解中就是把条件去掉,哈哈,简单粗暴的理解(不一定对哈)。 在条件去掉之后我还是希望我的因变量y是相互独立的,这时我们就需要给我们的条件,也就是随机效应u加一个变异Var(u) = G,那么此时y的边际分布就为: 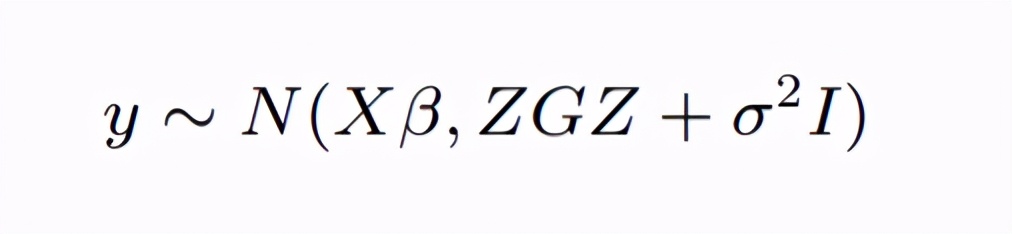
上面式子啥意思? 上面的式子告诉我们y和V = ZGZ0 + σ 2 I是有很大关系的,y的变化是依赖于固定效应以V为标准差进行变化的。 我们把上面的式子简化一下: 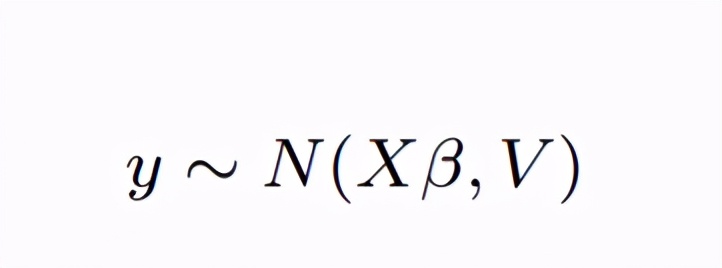
就是y的分布如上式,y是依赖于固定效应后以V为标准差进行变化的,所以我们要对y进行建模我们只需要设定好V,然后直接估计β就行?GEE就是这么一个思想。 写到这再给大家聊聊GEE和混合模型的区别: GEE估计的整体样本的均值,而混合模型也会对个体变异进行建模,一个是population average,一个是subject specific,这儿给大家推荐一篇文献,大家自己去琢磨琢磨(文献里面有写什么时候用GEE什么时候用混合模型哦) Szmaragd, C., Clarke, P., & Steele, F. (2013). Subject specific and population average models for binary longitudinal data: a tutorial. Longitudinal and life course studies, 4(2), 147-165. 边际模型的构建对于上面提到的响应y有相关的数据,我们可以通过边际模型进行处理,我们需要设定的参数有两个: 
以混合模型的思想理解,第一个就是固定效应如何,第二个就是变异如何。 做GEE的时候,我们认为不同个案之间的测量是独立的,同一个个案的不同测量是可以有相关的,和混合模型一样,只有systematic part(固定效应)才是我们关注的点,而Random part(随机效应)指数为了控制住统一观测不同测量之间的相关,这一部分是服务于固定效应估计的,并不是我们关注的点。(看下面的图片) 
在GEE中对随机效应的控制Random part是通过设定作业相关矩阵实现的。 
为啥叫作业相关矩阵呢,其实我们本来想要的是不同时点响应y的真实相关,但是这个不好得到,所以我们为了工作的继续进行,自己进行自认为合理的相关矩阵设定,所以叫作业相关矩阵,那么这个相关矩阵肯定就可以有很多种了,我们用例子数据一个一个来看: 一阶自相关AR(1)在我们的例子中y是测量了4次的,我现在假定测量之间的间隔时间越远其相关性α越低,那么我们的时点t和时点k的相关系数可以表示如下: 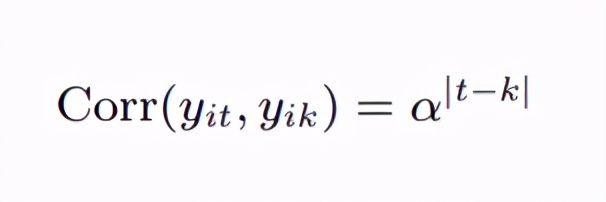
对于我们的例子,因为只有4个时点我们完全可以写出完整的相关结构矩阵: 
这个矩阵依然需要我们从数据中进行估计,比如我估计出来α为0.61,那么在的情况下我们的相关结构矩阵为下图: 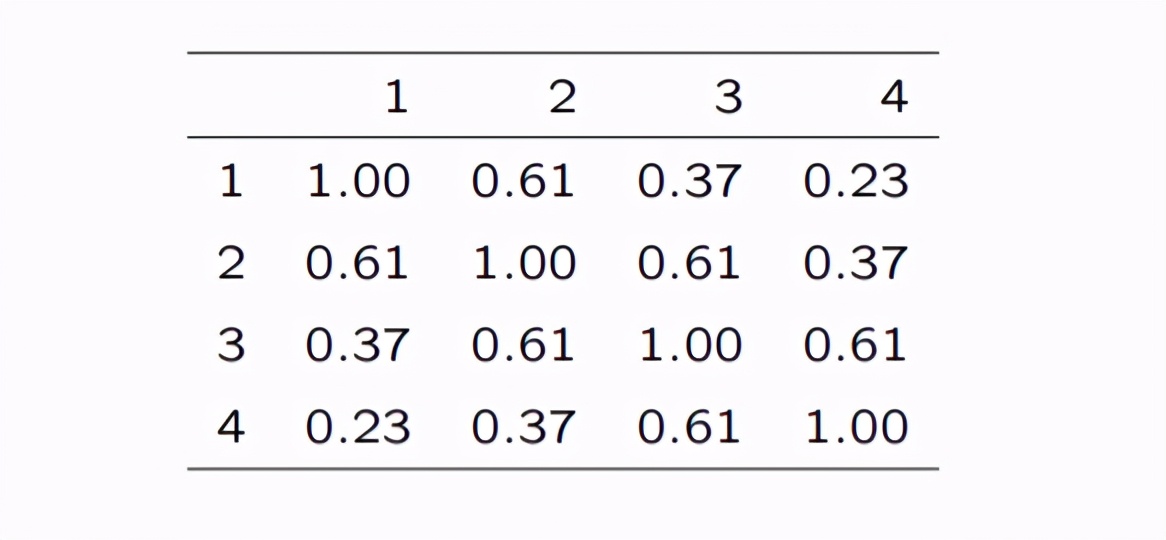
一阶自相关的意思就是隔得越远,相关越小。 等相关或者叫可交换的相关(exchangeable)大家肯定会说,你刚刚只是假定测量之间的间隔时间越远其相关性α越低,那么我是不是可以假定所有时间点的相关性都一样呢?(能问出这个问题的同学一看就是动脑子了) 当然可以啦,比如我就假定所有时点的相关都是相等的,为α: 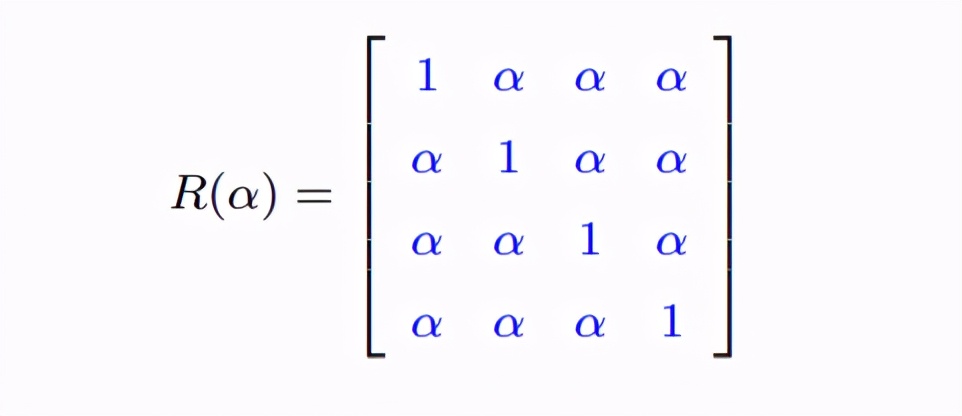
那么,此时我们假定α都一样时从数据中估计出来的α为0.46。 非确定相关(unstructured)相应地,你还可以假定每个不同时间点α都不一样,那么此时的相关结构就可以如下表示: 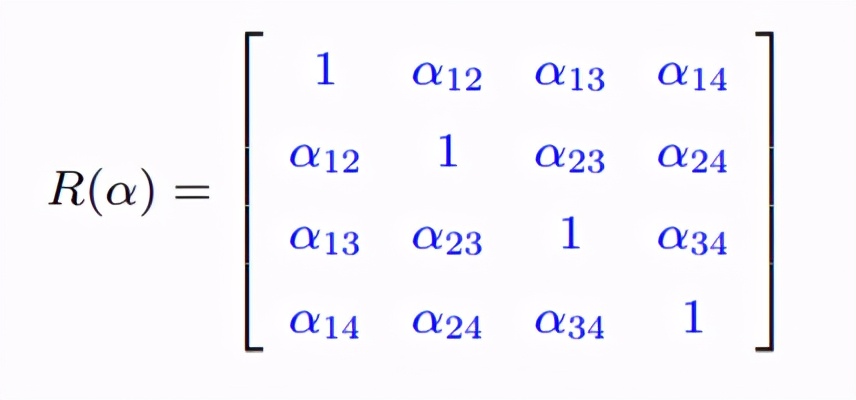
独立(independent) 还有一种理想情况就是重复测量之间是独立的: 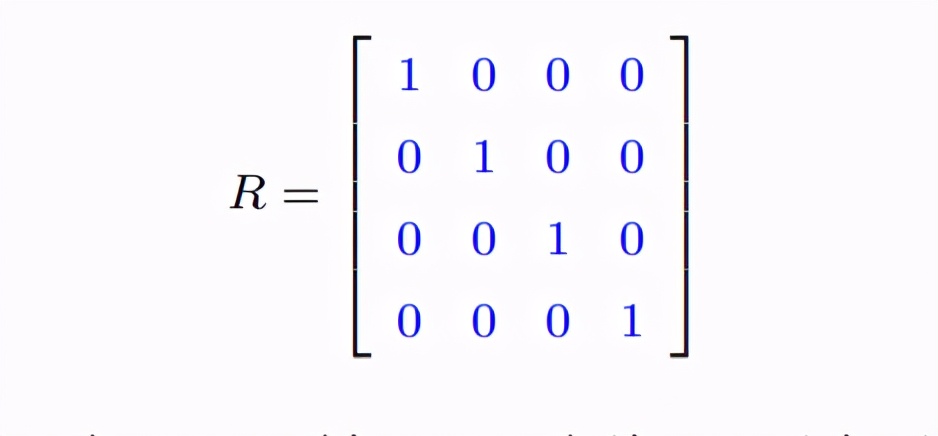
作业相关矩阵怎么选? 因为我们拿到数据的时候,我只知道这是一个纵向数据,我要用GEE,但是我肯定不是很确定作业相关矩阵到底是怎样的。 所以我们需要根据理论预先设定好,或者就是根据数据试,一个一个试 比如你测人的道德水平,一个月测一次,测了4次,你完全可以假定等相关嘛,因为短短4个月我们认为道德水平是不会变化的。 
如果要根据数据试,我们就有5种选择(见下图):1.所有的观测都是独立的(普通回归做就行),和4种不同的工作矩阵结构。 
对于每种选择,我们都相应地进行模型的系数估计,就可以得到下表的结果: 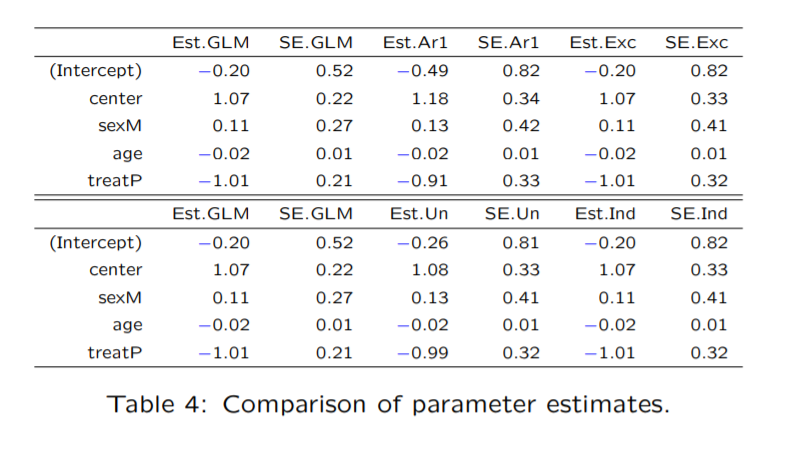
大家可以很清晰的看到:当我们将作业相关矩阵设置为独立(independent)和等相关(exchangeable)时,模型得到的系数估计就和混合模型的系数一样了。但是GEE的系数标准误要大一点。 这儿提醒大家的是,作业相关矩阵基本上根据常识设就行,不用纠结,影响不大的。 如何在R种做GEE这部分依然是用文章开头的例子给大家说明,来自两个病区(center=1,2)患有呼吸系统疾病共111个病人,分为治疗组(A)和安慰剂组(P),进行纵向随访4次,每一次随访我们会记录病人情况(1 = good, 0 = poor) 我们收来的数据大概长这样: 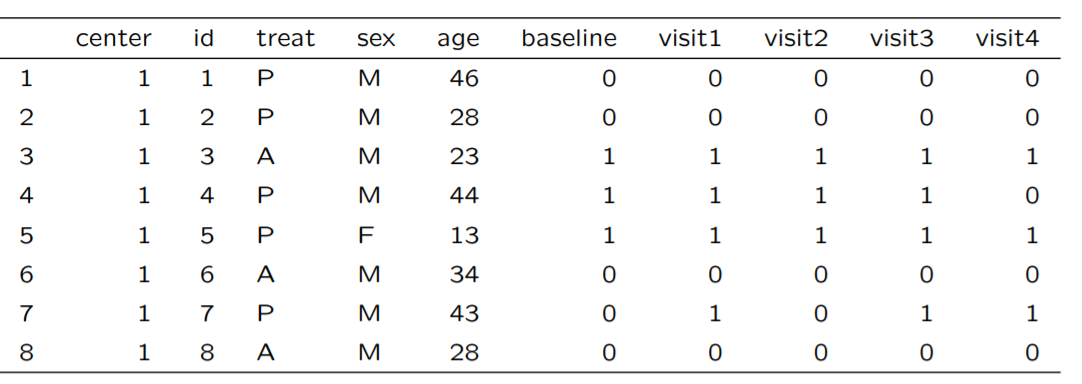
其中,我们的响应变量有4个,因为我们随访了4次嘛,但是我们的协变量center,treat,sex,age都是不随时间变化的。 如果我们不考虑个体之内的相关性,我们可以把上面的数据转化为长形数据直接做个逻辑斯蒂回归: m.glm |
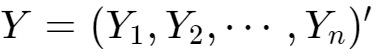 与自变量矩阵
与自变量矩阵 ,且
,且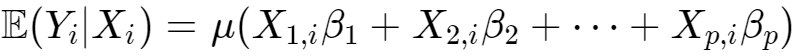
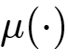 被称作均值函数,你把这个μ(⋅)想办法移到等号左边它就成了GLM中的连接函数。同时,我们假设
被称作均值函数,你把这个μ(⋅)想办法移到等号左边它就成了GLM中的连接函数。同时,我们假设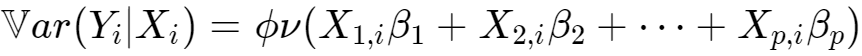
【本文地址】